Content from Introduction
Last updated on 2025-12-02 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How to perform differential expression analysis with Seurat?
Objectives
- Gain more familiarity with standard scRNA-seq Quality Control (QC) steps.
- Understand and get comfortable using various integration strategies
(
harmoyandseuratCCA). - Understand when and how to use all of the differential expression
functions offered by Seurat:
FindMarkers(),FindConservedMarkers(), andFindAllMarkers(). - Learn how to use differential expression tools meant for bulk data, like DESeq2, for single-cell ‘pseudobulk’ data and understand why you might choose this approach.
- Learn different ways to visualise both in-built Seurat functions and external packages like pheatmap.
This tutorial is partially based on existing material from:
Content from Setup, Quality Control and Sample Integration
Last updated on 2025-12-02 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How do we identify and remove low-quality cells in scRNA-seq data?
- What signs suggest batch effects between treatment conditions?
- When and why do we need to integrate datasets before downstream analysis?
- How do Harmony and Seurat CCA compare in aligning similar cell types?
Objectives
- Load and inspect a Seurat single-cell dataset (e.g., ifnb).
- Perform basic quality control and filtering using mitochondrial content and feature counts.
- Visualise data distributions with violin plots and scatterplots.
- Recognise when integration is needed and apply both Harmony and CCA integration methods.
- Perform initial clustering and visualise condition alignment in UMAP space.
Step 1. Load the packages and data
Today we’ll be working with Seurat (a popular scRNA-seq analysis package). SeuratData will be used to load in the experimental data we’re analysing. Tidyverse is a fundamental and very popularly used set of tools to wrangle and visualise data.
We’ll need to load the DESeq2 R package for when we explore pseudobulk DE approaches
pheatmap and grid are two really useful packages for creating custom heatmaps with our scRNA-seq data and exporting figures, respectively.
R
library(Seurat)
library(SeuratData)
library(tidyverse)
library(DESeq2)
library(patchwork)
library(pheatmap)
library(grid)
library(metap)
library(harmony)
library(DropletUtils)
library(ggplot2)
library(SingleR)
library(Celldex)
set.seed(4242) # Set Seed for Reproducibility
We’re using the ifnb public dataset provided by Seurat. This dataset contains PBMC data from 8 lupus patients before and after interferon beta treatment.
I strongly encourage you to explore the other datasets offered by the SeuratData package, it can be really good practice in your spare time.
The ifnb Seurat object we’re loading in here was originally made in
Seurat v4, there have since been a lot of changes from Seurat v4 to v5
so we’ll use the UpdateSeuratObject() function to update
the Seurat object so that it is compatible for today.
R
head(AvailableData()) # if you want to see the available SeuratData datasets use this function
R
InstallData("ifnb") # install our treatment vs control dataset for today
data("ifnb") # Load the dataset into our current R script
ifnb <- UpdateSeuratObject(ifnb) # Make sure the seurat object is in the format of Seurat v5
str(ifnb) # we can use this to take a look at the information in our Seurat Object
Challenge
Looking at the output from the str() function above, can
you tell whether this seurat object is processed or unprocessed?
When loading in seurat objects, we can have a look at what processing steps have been performed on it by using the str() function. In the output we can tell that the ifnb Seurat object is unprocessed because the scale.data slot is empty, no variable features have been identified, and no dimensionality reduction functions have been performed.
Step 2: Run QC, filter out low quality cells
Lets start by processing our data (run the standard seurat workflow steps including preprocessing and filtering).
First we need to take a look at QC metrics, then decide on the thresholds for filtering.
Challenge
QC for droplet-based protocols
In droplet-based protocols (e.g., 10x Genomics), millions of droplets are formed, but only some droplets contain exactly one real cell. Several types of “bad droplets” appear:
- Empty droplets (no real cell)
- Doublets (two cells in one droplet)
R
# Step 2a: QC and filtering
ifnb$percent.mt <- PercentageFeatureSet(object = ifnb, pattern = "^MT-") # First let's annotate the mitochondrial percentage for each cell
head((ifnb@meta.data)) # we can take a look mitochondrial percentages for the seurat object by viewing the seurat objects metadata
OUTPUT
orig.ident nCount_RNA nFeature_RNA stim seurat_annotations
AAACATACATTTCC.1 IMMUNE_CTRL 3017 877 CTRL CD14 Mono
AAACATACCAGAAA.1 IMMUNE_CTRL 2481 713 CTRL CD14 Mono
AAACATACCTCGCT.1 IMMUNE_CTRL 3420 850 CTRL CD14 Mono
AAACATACCTGGTA.1 IMMUNE_CTRL 3156 1109 CTRL pDC
AAACATACGATGAA.1 IMMUNE_CTRL 1868 634 CTRL CD4 Memory T
AAACATACGGCATT.1 IMMUNE_CTRL 1581 557 CTRL CD14 Mono
percent.mt
AAACATACATTTCC.1 0
AAACATACCAGAAA.1 0
AAACATACCTCGCT.1 0
AAACATACCTGGTA.1 0
AAACATACGATGAA.1 0
AAACATACGGCATT.1 0R
# Step 2b: Visualise QC metrics and identify filtering thresholds
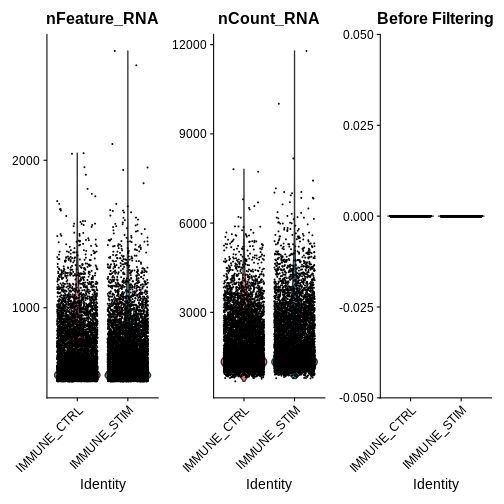
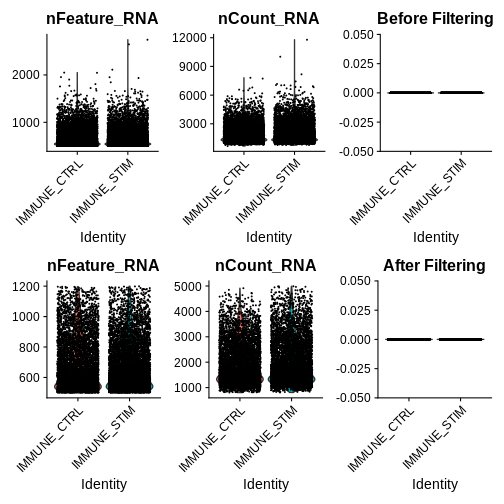
qc.metric.plts <- VlnPlot(ifnb, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3) +
ggtitle("Before Filtering")
WARNING
Warning in SingleExIPlot(type = type, data = data[, x, drop = FALSE], idents =
idents, : All cells have the same value of percent.mt.R
association.plt.raw <- FeatureScatter(ifnb, feature1 = "nCount_RNA", feature2 = "nFeature_RNA") + geom_smooth(method = "lm") +
ggtitle("Before Filtering")
qc.metric.plts
R
association.plt.raw
OUTPUT
`geom_smooth()` using formula = 'y ~ x'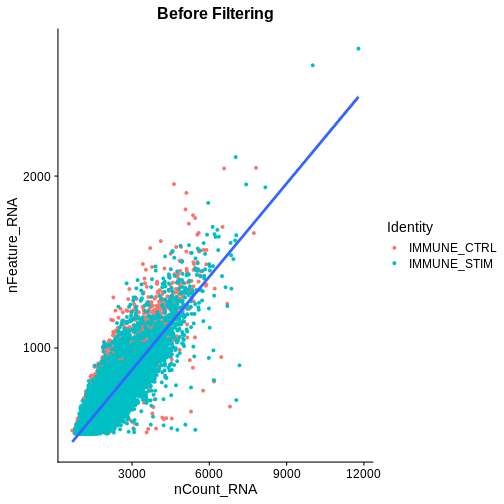
Looking at the violin plots of QC metrics, what do you think about the overall quality of the ifnb dataset?
After visualising QC metrics, we’ll move on to the actual filtering
R
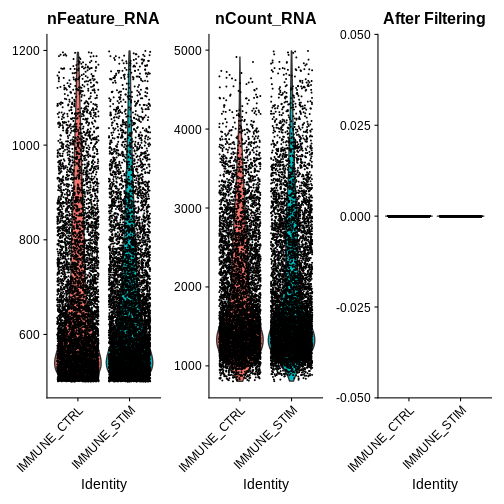
# Step 2c: filter out low-quality cells + visualise the metrics for our filtered seurat object
ifnb.filtered <- subset(ifnb, subset = nCount_RNA > 800 &
nCount_RNA < 5000 &
nFeature_RNA > 200 &
nFeature_RNA < 1200 &
percent.mt < 5)
qc.metric.plts.filtered <- VlnPlot(ifnb.filtered, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3) +
ggtitle("After Filtering")
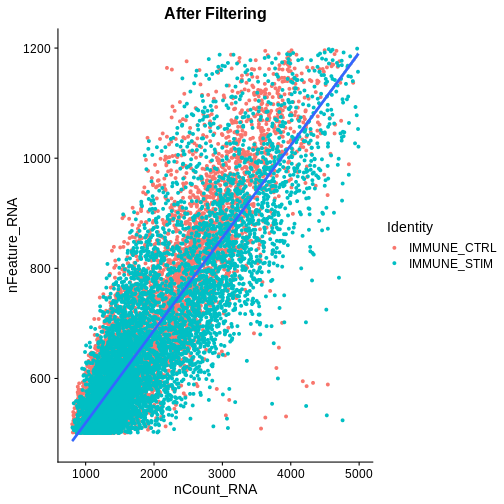
association.plt.filtered <- FeatureScatter(ifnb.filtered, feature1 = "nCount_RNA", feature2 = "nFeature_RNA") + geom_smooth(method = "lm") +
ggtitle("After Filtering")
qc.metric.plts.filtered
R
association.plt.filtered
Let’s check how many cells we’ve filtered out (looks like ~400 cells were removed):
R
## Defining a couple helper functions to standardise x and y axis for two plots
get_plot_range <- function(plot) {
data <- layer_data(plot)
list(
x = range(data$x, na.rm = TRUE),
y = range(data$y, na.rm = TRUE)
)
}
standardise_plt_scale <- function(plt1, plt2){
# Get ranges for both plots
range_raw <- get_plot_range(plt1)
range_filtered <- get_plot_range(plt2)
# Calculate overall range
x_range <- range(c(range_raw$x, range_filtered$x))
y_range <- range(c(range_raw$y, range_filtered$y))
suppressMessages({
# Update both plots with the same x and y scales
association.plt.raw <- association.plt.raw +
scale_x_continuous(limits = x_range) +
scale_y_continuous(limits = y_range)
association.plt.filtered <- association.plt.filtered +
scale_x_continuous(limits = x_range) +
scale_y_continuous(limits = y_range)
})
# Wrap the plots
wrapped_plots <- wrap_plots(list(association.plt.raw, association.plt.filtered),
ncol = 2)
return(wrapped_plots)
}
wrap_plots(list(qc.metric.plts, qc.metric.plts.filtered),
ncol = 1)
R
association.plts <- standardise_plt_scale(association.plt.raw,
association.plt.filtered)
association.plts
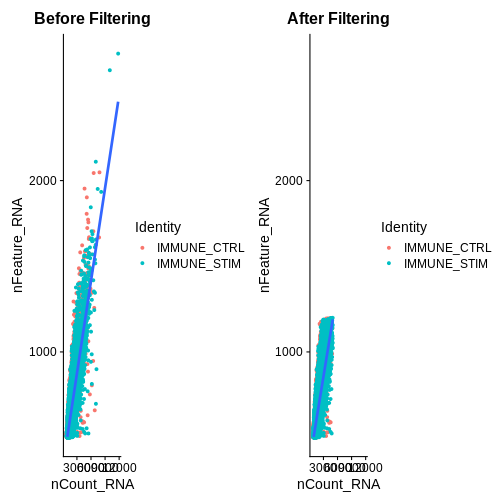
Let’s check how many cells we’ve filtered out (looks like ~400 cells were removed):
R
ifnb
OUTPUT
An object of class Seurat
14053 features across 13999 samples within 1 assay
Active assay: RNA (14053 features, 0 variable features)
2 layers present: counts, dataR
ifnb.filtered
OUTPUT
An object of class Seurat
14053 features across 13548 samples within 1 assay
Active assay: RNA (14053 features, 0 variable features)
2 layers present: counts, dataNext we need to split our count matrices based on conditions. This step stores stimulated versus unstimulated expression information separately, creating a list of RNA assays grouped by the “stim” condition. Note: this is important for downstream integration steps in Seurat v5.
R
ifnb.filtered[["RNA"]] <- split(ifnb.filtered[["RNA"]], f = ifnb.filtered$stim) # Lets split our count matrices based on conditions (stored within different layers) -> needed for integration steps in Seurat v5
Step 3: Before performing differential expression between the two conditions, let’s assess whether we need to integrate our data
After filtering out low quality cells, we want to visualise our data to see how cells group by condition and if we need to perform batch-effect correction (integration)
R
ifnb.filtered <- NormalizeData(ifnb.filtered)
OUTPUT
Normalizing layer: counts.CTRLOUTPUT
Normalizing layer: counts.STIMR
ifnb.filtered <- FindVariableFeatures(ifnb.filtered)
OUTPUT
Finding variable features for layer counts.CTRLOUTPUT
Finding variable features for layer counts.STIMR
ifnb.filtered <- ScaleData(ifnb.filtered)
OUTPUT
Centering and scaling data matrixR
## Centering and scaling data matrix
ifnb.filtered <- RunPCA(ifnb.filtered)
OUTPUT
PC_ 1
Positive: TYROBP, C15orf48, FCER1G, CST3, SOD2, ANXA5, FTL, TYMP, TIMP1, CD63
LGALS1, CTSB, S100A4, KYNU, LGALS3, FCN1, PSAP, NPC2, ANXA2, IGSF6
S100A11, LYZ, SPI1, APOBEC3A, CD68, CTSL, NINJ1, HLA-DRA, CCL2, SDCBP
Negative: NPM1, CCR7, CXCR4, GIMAP7, LTB, CD3D, CD7, SELL, TMSB4X, CD2
TRAT1, IL7R, PTPRCAP, IL32, ITM2A, RGCC, LEF1, CD3G, ALOX5AP, CREM
PASK, MYC, SNHG8, TSC22D3, BIRC3, GPR171, NOP58, CD27, RARRES3, CD8B
PC_ 2
Positive: ISG15, ISG20, IFIT3, IFIT1, LY6E, TNFSF10, IFIT2, MX1, IFI6, RSAD2
CXCL10, OAS1, CXCL11, IFITM3, MT2A, OASL, TNFSF13B, IDO1, IL1RN, APOBEC3A
CCL8, GBP1, HERC5, FAM26F, GBP4, RABGAP1L, HES4, WARS, VAMP5, DEFB1
Negative: IL8, CLEC5A, CD14, VCAN, S100A8, IER3, MARCKSL1, IL1B, PID1, CD9
GPX1, INSIG1, PHLDA1, PLAUR, PPIF, THBS1, OSM, SLC7A11, CTB-61M7.2, GAPDH
LIMS1, S100A9, GAPT, ACTB, CXCL3, C19orf59, MGST1, OLR1, CEBPB, FTH1
PC_ 3
Positive: HLA-DQA1, CD83, HLA-DQB1, CD74, HLA-DRA, HLA-DPA1, HLA-DRB1, CD79A, HLA-DPB1, IRF8
MS4A1, SYNGR2, MIR155HG, HERPUD1, REL, HSP90AB1, ID3, HLA-DMA, TVP23A, FABP5
NME1, HSPE1, PMAIP1, BANK1, CD70, HSPD1, TSPAN13, EBI3, TCF4, CCR7
Negative: ANXA1, GNLY, NKG7, GIMAP7, TMSB4X, PRF1, CD7, CCL5, RARRES3, CD3D
CD2, KLRD1, GZMH, GZMA, CTSW, GZMB, FGFBP2, CLIC3, IL32, MT2A
FASLG, KLRC1, CST7, RGCC, CD8A, GCHFR, OASL, GZMM, CXCR3, KLRB1
PC_ 4
Positive: LTB, SELL, CCR7, LEF1, IL7R, CD3D, TRAT1, GIMAP7, ADTRP, PASK
CD3G, TSHZ2, CMTM8, SOCS3, TSC22D3, NPM1, CCL2, MYC, CCL7, CCL8
CTSL, SNHG8, TXNIP, CD27, S100A9, CA6, C12orf57, TMEM204, HPSE, GPR171
Negative: NKG7, GZMB, GNLY, CST7, PRF1, CCL5, CLIC3, KLRD1, APOBEC3G, GZMH
GZMA, CTSW, FGFBP2, KLRC1, FASLG, C1orf21, HOPX, SH2D1B, TNFRSF18, CXCR3
LINC00996, SPON2, RAMP1, ID2, GCHFR, IGFBP7, HLA-DPA1, CD74, XCL2, HLA-DPB1
PC_ 5
Positive: CCL2, CCL7, CCL8, PLA2G7, TXN, LMNA, SDS, S100A9, CSTB, ATP6V1F
CAPG, CCR1, EMP1, FABP5, CCR5, IDO1, TPM4, LILRB4, MGST1, CTSB
HPSE, CCNA1, GCLM, PDE4DIP, HSPA1A, CD63, SLC7A11, HSPA5, VIM, HSP90B1
Negative: VMO1, FCGR3A, MS4A4A, CXCL16, MS4A7, PPM1N, HN1, LST1, SMPDL3A, ATP1B3
CASP5, CDKN1C, AIF1, CH25H, PLAC8, SERPINA1, TMSB4X, LRRC25, CD86, GBP5
HCAR3, RP11-290F20.3, COTL1, RGS19, VNN2, PILRA, STXBP2, LILRA5, C3AR1, FCGR3B R
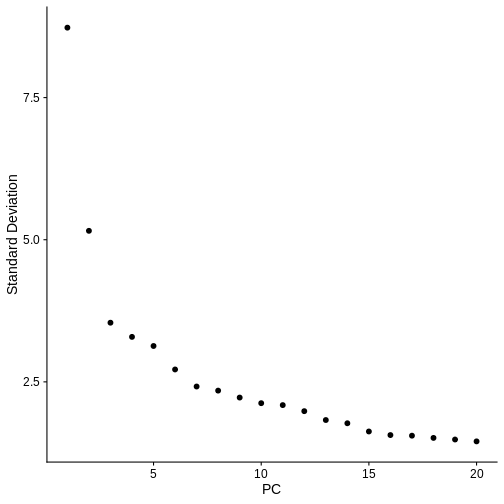
ElbowPlot(ifnb.filtered) # Visualise the dimensionality of the data, looks like 15 PCs is adequate to capture the majority of the variation in the data, but we'll air on the higher side and consider all 20 dimensions.
R
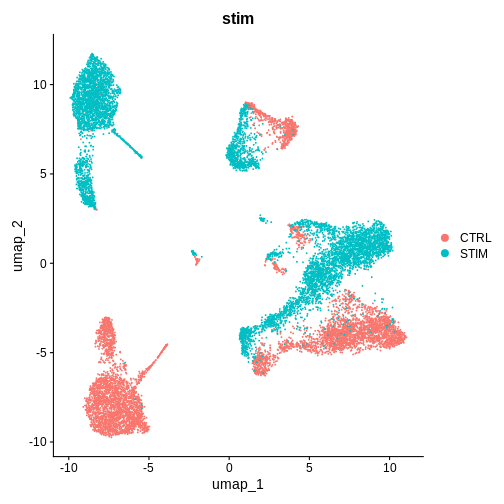
DimPlot(ifnb.filtered, reduction = 'pca', group.by = 'stim') # lets see how our cells separate by condition and whether integration is necessary
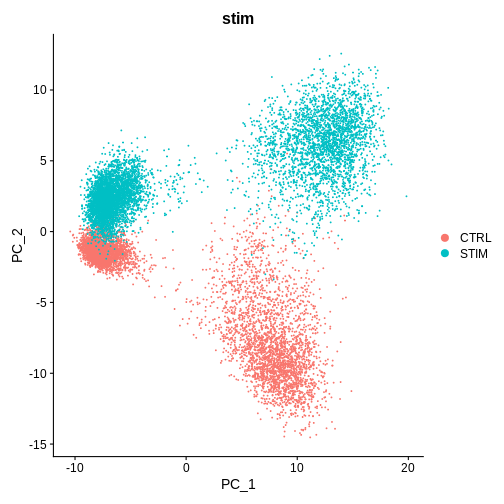
Challenge
Cell Cycle Check 1 — BEFORE integration (after PCA / pre-Harmony / CCA)
Seurat also features a function,
CellCyleScoring to calculate which phase each individual
cell is in the cell cycle using canonical markers. You can read more
about it here.
Which phase in the cell cycle are the clusters in primarily? Are they different or the same between clusters?
R
# ---- Cell-cycle check (PRE-integration) ----
if (!exists("cc.genes.updated.2019")) data("cc.genes.updated.2019", package = "Seurat")
# Score S/G2M
ifnb.filtered <- CellCycleScoring(
ifnb.filtered,
s.features = cc.genes.updated.2019$s.genes,
g2m.features = cc.genes.updated.2019$g2m.genes,
set.ident = FALSE,
search = TRUE
)
# Quick UMAP on PCA (if you haven't already run it)
if (!"umap" %in% Reductions(ifnb.filtered)) {
ifnb.filtered <- RunUMAP(ifnb.filtered, dims = 1:20, reduction = "pca")
}
# Visual + quick quant
DimPlot(ifnb.filtered, reduction = "umap", group.by = "Phase", pt.size = 0.3)
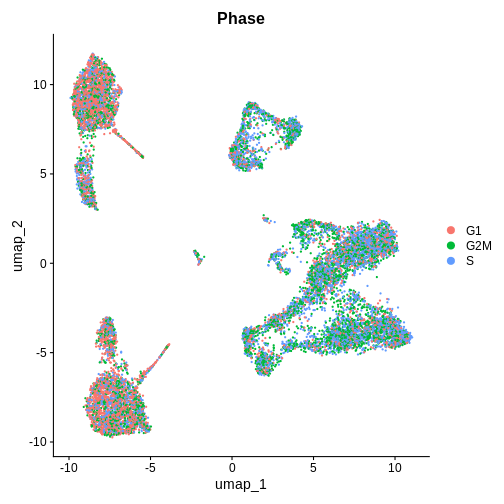
R
emb_pca <- Embeddings(ifnb.filtered, "pca")[,1:20]
pc_cor_S <- sapply(1:20, \(i) cor(emb_pca[,i], ifnb.filtered$S.Score))
pc_cor_G2M <- sapply(1:20, \(i) cor(emb_pca[,i], ifnb.filtered$G2M.Score))
print(cbind(PC=1:20, r_S=round(pc_cor_S,3), r_G2M=round(pc_cor_G2M,3)))
OUTPUT
PC r_S r_G2M
[1,] 1 -0.262 -0.245
[2,] 2 0.065 0.048
[3,] 3 0.023 0.038
[4,] 4 0.002 -0.020
[5,] 5 -0.003 0.015
[6,] 6 -0.003 0.090
[7,] 7 -0.045 -0.038
[8,] 8 0.007 -0.010
[9,] 9 -0.014 0.012
[10,] 10 -0.021 -0.061
[11,] 11 -0.006 0.064
[12,] 12 -0.008 0.008
[13,] 13 0.031 0.042
[14,] 14 0.008 -0.027
[15,] 15 0.011 0.015
[16,] 16 -0.014 -0.007
[17,] 17 -0.010 0.011
[18,] 18 0.009 0.006
[19,] 19 0.003 0.027
[20,] 20 -0.015 0.026These are PBMCs before and after treatment, there should be cells that are similar between both conditions, it looks like we’ll have to run some batch effect correction to overlay similar cell-types from both conditions to perform downstream analysis.
Do you think we need to integrate our data? Hint: Look at the UMAP and PC1/PC2 plots we made above
What do you think would happen if we were to perform unsupervised clustering right now, without integrating our data (or overlaying similar cells on top of each other from both conditions)?
Step 4: Integrating our data using the harmony method
Seurat v5 has made it really easy to test different integration methods quickly, let’s use a really popular approach (harmony) first.
R
# code adapted from: https://satijalab.org/seurat/articles/seurat5_integration
ifnb.filtered <- IntegrateLayers(object = ifnb.filtered,
method = HarmonyIntegration,
orig.reduction = "pca",
new.reduction = "harmony")
OUTPUT
The `features` argument is ignored by `HarmonyIntegration`.
Transposing data matrix
Using automatic lambda estimation
Initializing state using k-means centroids initialization
Harmony 1/10
Harmony 2/10
Harmony 3/10
Harmony converged after 3 iterations
This message is displayed once per session.R
ifnb.filtered <- RunUMAP(ifnb.filtered, reduction = "harmony", dims = 1:20, reduction.name = "umap.harmony")
OUTPUT
00:44:41 UMAP embedding parameters a = 0.9922 b = 1.112
00:44:41 Read 13548 rows and found 20 numeric columns
00:44:41 Using Annoy for neighbor search, n_neighbors = 30
00:44:41 Building Annoy index with metric = cosine, n_trees = 50
0% 10 20 30 40 50 60 70 80 90 100%
[----|----|----|----|----|----|----|----|----|----|
**************************************************|
00:44:43 Writing NN index file to temp file /tmp/RtmpKAZjB2/file272b67635406
00:44:43 Searching Annoy index using 1 thread, search_k = 3000
00:44:47 Annoy recall = 100%
00:44:48 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 30
00:44:50 Initializing from normalized Laplacian + noise (using RSpectra)
00:44:51 Commencing optimization for 200 epochs, with 586822 positive edges
00:44:51 Using rng type: pcg
00:44:57 Optimization finishedR
after.harmony <- DimPlot(ifnb.filtered, reduction = "umap.harmony", group.by = "stim") +
ggtitle("After Harmony Integration")
before.integration <- DimPlot(ifnb.filtered, reduction = "umap", group.by = "stim") +
ggtitle("Before Integration")
before.integration | after.harmony
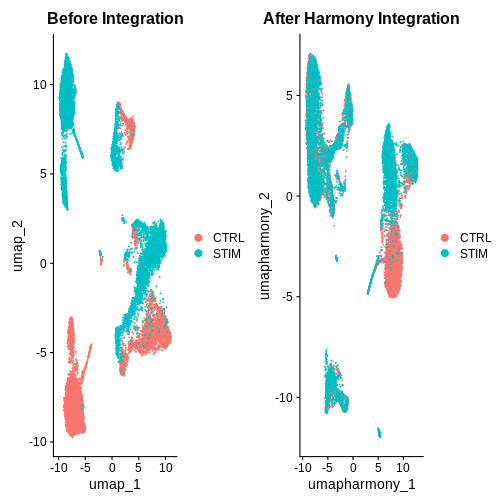
Looking at the UMAPs above, do you think integration was successful?
Step 5: Integrating our data using an alternative Seurat CCA method
R
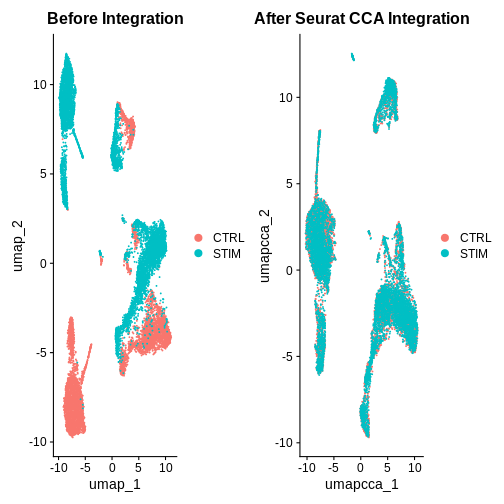
ifnb.filtered <- IntegrateLayers(object = ifnb.filtered,
method = CCAIntegration,
orig.reduction = "pca",
new.reduction = "integrated.cca")
ifnb.filtered <- RunUMAP(ifnb.filtered, reduction = "integrated.cca", dims = 1:20, reduction.name = "umap.cca")
after.seuratCCA <- DimPlot(ifnb.filtered, reduction = "umap.cca", group.by = "stim") +
ggtitle("After Seurat CCA Integration")
before.integration | after.seuratCCA
R
after.harmony | after.seuratCCA
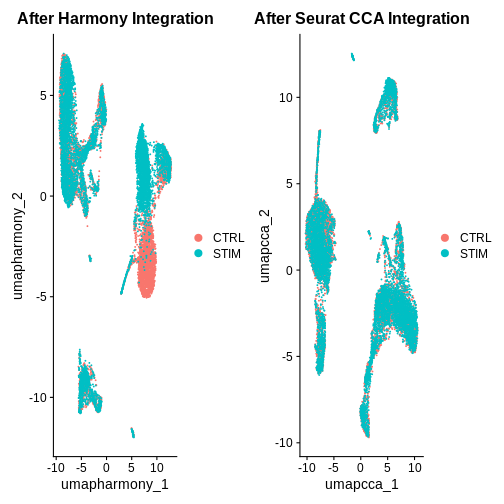
R
## Show example slide of integration 'failing' but due to different cell types in each sample ***
What do you think of the integration results now?
Hint: Also look at the PC1 and PC2 plots for each integration method.
Challenge
Cell Cycle Check 2 — AFTER integration (after umap.cca + clustering)
Now that we have integrated the data, do you think the results will be the same or different?
R
# ---- Cell-cycle check (POST-integration) ----
# Visual on integrated embedding
DimPlot(ifnb.filtered, reduction = "umap.cca", group.by = "Phase", pt.size = 0.3)
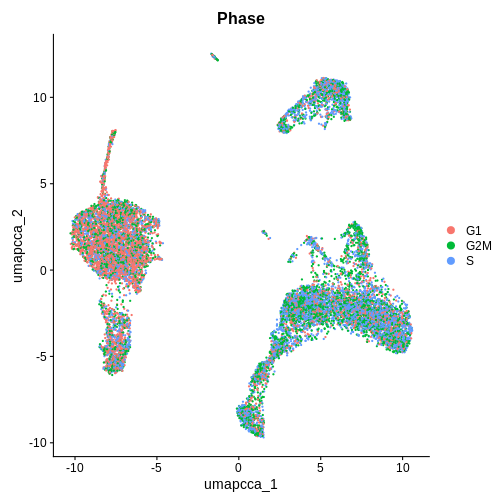
R
# Phase composition by cluster and by condition
tab_phase_cluster <- prop.table(table(ifnb.filtered$seurat_clusters, ifnb.filtered$Phase), 1) * 100
ERROR
Error in `x[[i, drop = TRUE]]` at SeuratObject/R/seurat.R:2939:3:
! 'seurat_clusters' not found in this Seurat object
Did you mean "seurat_annotations"?R
tab_phase_cond <- prop.table(table(ifnb.filtered$stim, ifnb.filtered$Phase), 1) * 100
pheatmap(tab_phase_cluster,
main = "Phase (%) by cluster",
display_numbers = TRUE,
number_format = "%.1f")
ERROR
Error: object 'tab_phase_cluster' not foundR
pheatmap(tab_phase_cond, main = "Phase (%) by condition (stim)")
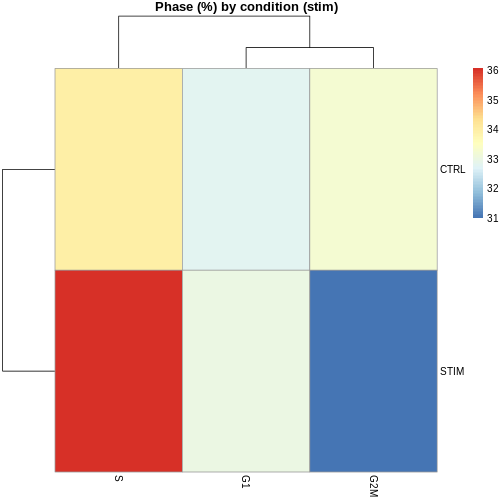
Step 6: Perform standard clustering steps after integration
This step collapses individual control and treatment datasets together and needs to be done before differential expression analysis
R
ifnb.filtered <- FindNeighbors(ifnb.filtered, reduction = "integrated.cca", dims = 1:20)
OUTPUT
Computing nearest neighbor graphOUTPUT
Computing SNNR
ifnb.filtered <- FindClusters(ifnb.filtered, resolution = 0.5)
OUTPUT
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 13548
Number of edges: 521570
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9002
Number of communities: 13
Elapsed time: 2 secondsR
ifnb.filtered <- JoinLayers(ifnb.filtered)
Additional Challenges
Challenge
You can also use K-means clustering to cluster the data to compare to
other clustering methods. How can you use the kmeans()
function from stats to cluster the data and visualise it
using DimPlot()?
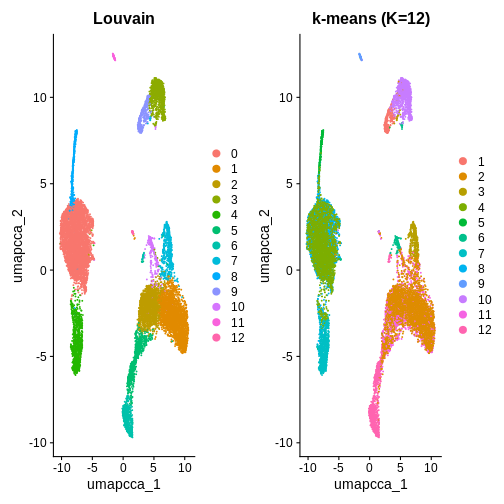
In this example, we used k = 5 purely for illustration. As you can see, it produces fewer clusters compared to the default Louvain algorithm. You are welcome to try different k values in your own time to explore whether k-means clustering is a suitable option in this context.
R
# K-means
emb <- Embeddings(ifnb.filtered, "pca")[, 1:20]
set.seed(1)
km <- kmeans(emb, centers = 12, nstart = 50)
ifnb.filtered$kmeans_k12 <- factor(km$cluster)
# Compare labelings
p1 <- DimPlot(ifnb.filtered, reduction = "umap.cca", group.by = "seurat_clusters") + ggtitle("Louvain")
p2 <- DimPlot(ifnb.filtered, reduction = "umap.cca", group.by = "kmeans_k12") + ggtitle("k-means (K=12)")
p1 | p2
R
# If you decide to proceed with k-means downstream:
Idents(ifnb.filtered) <- "kmeans_k12"
- QC filtering removes low-quality cells (e.g., low gene count or high mitochondrial %).
- Integration corrects sample-to-sample variation so cells group by biology, not by batch.
- Harmony and CCA both align shared cell states but use different mathematical strategies.
Content from Differential Gene Expression when dealing with two treatment conditions
Last updated on 2025-12-02 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How do conserved markers help us label clusters reliably across conditions?
- What exactly do avg_log2FC, pct.1, pct.2, and p_val_adj mean in FindMarkers?
- Why must DE be run within a cell type (e.g., CD16 Mono_STIM vs CD16 Mono_CTRL) rather than “all cells”?
Objectives
- Use FindConservedMarkers() to pick markers and label clusters.
- Set identities to annotations and create compound identities (celltype.and.stim) for clean contrasts.
- Run FindMarkers() to get DEGs between conditions within a cell type and interpret key columns.
- Visualize DEGs (FeaturePlot with split.by, DoHeatmap / pheatmap) and export results for downstream use.
- Recognize pitfalls (composition effects, inappropriate contrasts, overly lenient thresholds).
OUTPUT
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 13548
Number of edges: 521570
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9002
Number of communities: 13
Elapsed time: 2 secondsR
DimPlot(ifnb.filtered, reduction = "umap.cca", label = T)
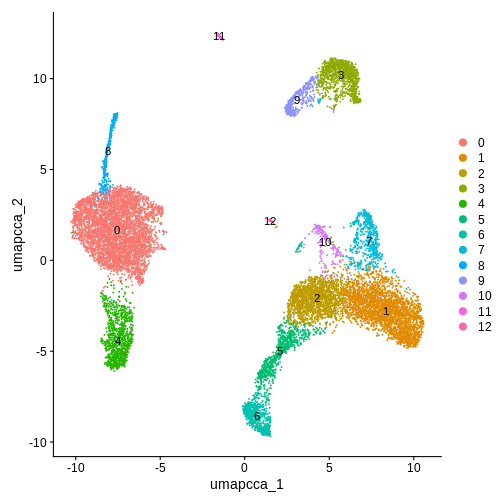
R
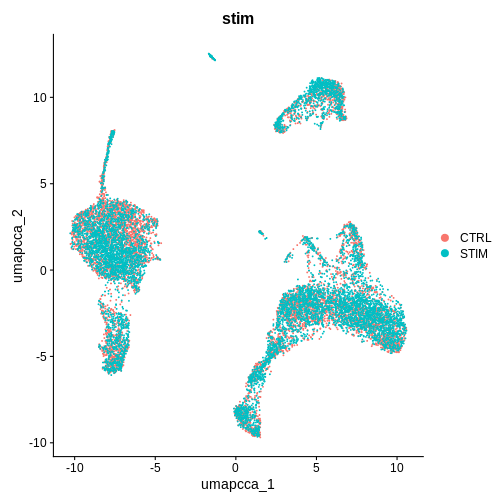
DimPlot(ifnb.filtered, reduction = "umap.cca", group.by = "stim")
Step 1. Find Conserved Markers to label our celltypes
R
## Let's look at conserved markers in cluster 4 across our two conditions (compared to all other clusters)
markers.cluster.4 <- FindConservedMarkers(ifnb.filtered, ident.1 = 4,
grouping.var = 'stim')
OUTPUT
Testing group CTRL: (4) vs (0, 11, 2, 7, 1, 5, 10, 9, 3, 6, 8, 12)OUTPUT
For a (much!) faster implementation of the Wilcoxon Rank Sum Test,
(default method for FindMarkers) please install the presto package
--------------------------------------------
install.packages('devtools')
devtools::install_github('immunogenomics/presto')
--------------------------------------------
After installation of presto, Seurat will automatically use the more
efficient implementation (no further action necessary).
This message will be shown once per sessionOUTPUT
Testing group STIM: (4) vs (5, 11, 1, 3, 0, 7, 9, 2, 6, 8, 10, 12)R
head(markers.cluster.4)
OUTPUT
CTRL_p_val CTRL_avg_log2FC CTRL_pct.1 CTRL_pct.2 CTRL_p_val_adj
VMO1 0.000000e+00 6.020340 0.843 0.060 0.000000e+00
FCGR3A 0.000000e+00 4.127801 0.980 0.204 0.000000e+00
MS4A7 0.000000e+00 3.734967 0.957 0.196 0.000000e+00
MS4A4A 0.000000e+00 5.200846 0.587 0.025 0.000000e+00
CXCL16 1.976263e-323 2.928346 0.949 0.234 2.777242e-319
LST1 8.070733e-289 2.861452 0.929 0.251 1.134180e-284
STIM_p_val STIM_avg_log2FC STIM_pct.1 STIM_pct.2 STIM_p_val_adj
VMO1 0 7.585467 0.721 0.022 0
FCGR3A 0 5.121272 0.989 0.128 0
MS4A7 0 3.916774 0.992 0.219 0
MS4A4A 0 4.824831 0.901 0.073 0
CXCL16 0 3.854043 0.924 0.148 0
LST1 0 3.059542 0.887 0.193 0
max_pval minimump_p_val
VMO1 0.000000e+00 0
FCGR3A 0.000000e+00 0
MS4A7 0.000000e+00 0
MS4A4A 0.000000e+00 0
CXCL16 1.976263e-323 0
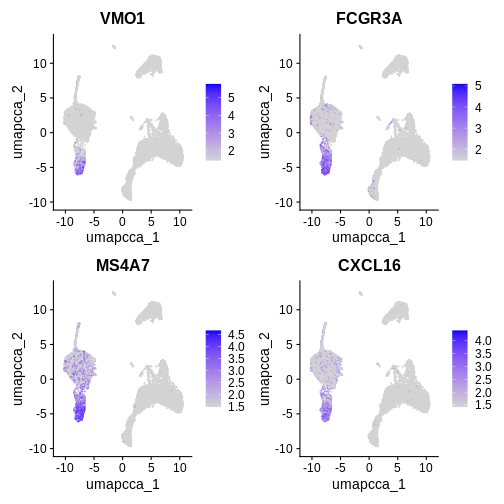
LST1 8.070733e-289 0Let’s visualise the top upregulated, conserved between condition,
marker genes identified in cluster 4 using the
FeaturePlot() function.
Try running the function in the code block below without defining a min.cutoff, or changing the value of the min.cutoff parameter.
R
# Try looking up some of these markers here: https://www.proteinatlas.org/
FeaturePlot(ifnb.filtered, reduction = "umap.cca",
features = c('VMO1', 'FCGR3A', 'MS4A7', 'CXCL16'), min.cutoff = 'q10')
R
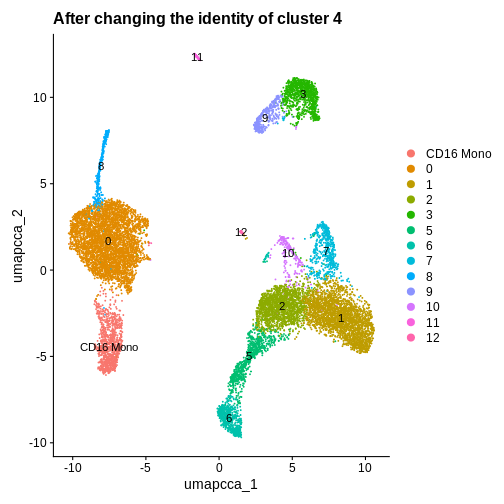
# I happen to know that the cells in cluster 4 are CD16 monocytes - lets rename this cluster
# Idents(ifnb.filtered) # Let's look at the identities of our cells at the moment
R
ifnb.filtered <- RenameIdents(ifnb.filtered, '4' = 'CD16 Mono') # Let's rename cells in cluster 4 with a new cell type label
# Idents(ifnb.filtered) # we can take a look at the cell identities again
R
DimPlot(ifnb.filtered, reduction = "umap.cca", label = T) +
ggtitle("After changing the identity of cluster 4")
Step 2: Set the identity of our clusters to the annotations provided
R
Idents(ifnb.filtered) <- ifnb.filtered@meta.data$seurat_annotations
# Idents(ifnb.filtered)
R
DimPlot(ifnb.filtered, reduction = "umap.cca", label = T)
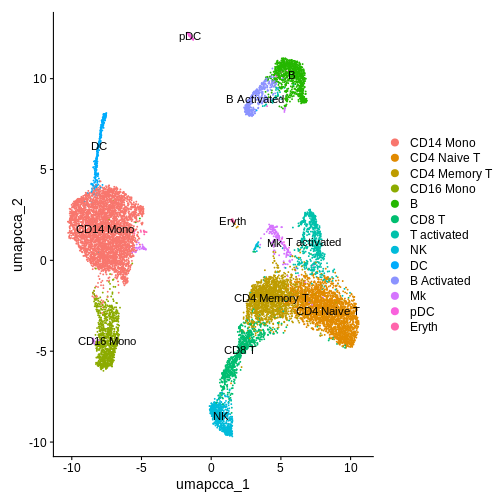
If you want to perform cell-type identification on your own data when you don’t have a ground-truth, using automatic cell type annotation methods can be a good starting point. This approach is discussed in more detail in the Intro to scRNA-seq workshop material.
Challenge
Automated Cell Type Annotation
R
# Load reference data
# Blood & immune lineages
ref.set <- celldex::BlueprintEncodeData()
ifnb.v4 <- JoinLayers(ifnb.filtered)
sce.ifnb.filtered <- as.SingleCellExperiment(ifnb.v4)
sce.ifnb.filtered <- logNormCounts(sce.ifnb.filtered)
pred.cnts <- SingleR(
test = sce.ifnb.filtered,
ref = ref.set,
labels = ref.set$label.main
)
lbls.keep <- table(pred.cnts$labels)>10
# Add SingleR labels to Seurat metadata
ifnb.filtered$SingleR.labels <- sce.ifnb.filtered$SingleR.labels
ifnb.filtered$SingleR.labels <- ifelse(lbls.keep[pred.cnts$labels], pred.cnts$labels, 'Other')
# Run UMAP (based on PCA)
ifnb.filtered <- RunUMAP(ifnb.filtered, dims = 1:20)
DimPlot(ifnb.filtered, reduction='umap.cca', group.by='SingleR.labels', label = TRUE, label.size = 3 )
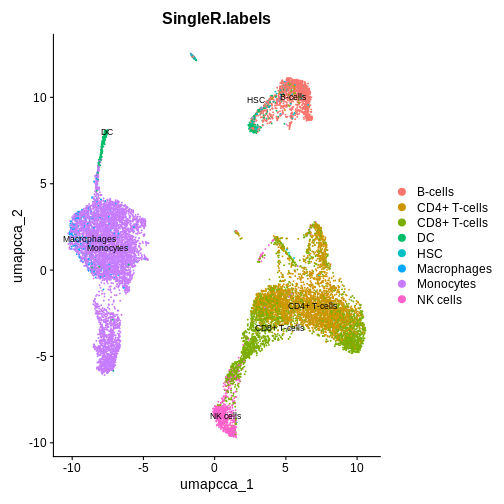
Step 3: Find differentially expressed genes (DEGs) between our two conditions, using CD16 Mono cells as an example
R
# Make another column in metadata showing what cells belong to each treatment group (This will make more sense in a bit)
ifnb.filtered$celltype.and.stim <- paste0(ifnb.filtered$seurat_annotations, '_', ifnb.filtered$stim)
# (ifnb.filtered@meta.data)
Idents(ifnb.filtered) <- ifnb.filtered$celltype.and.stim
DimPlot(ifnb.filtered, reduction = "umap.cca", label = T) # each cluster is now made up of two labels (control or stimulated)
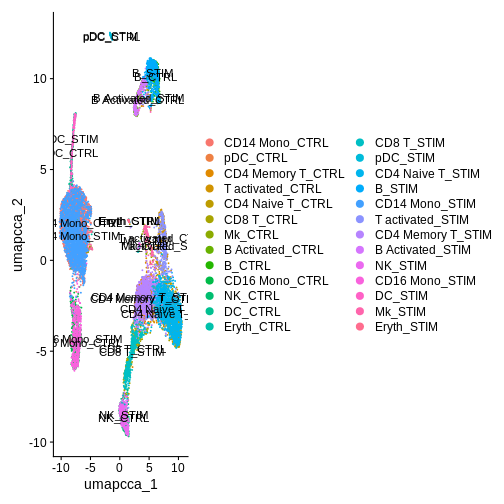
R
DimPlot(ifnb.filtered, reduction = "umap.cca",
label = T, split.by = "stim") # Lets separate by condition to see what we've done a bit more clearly
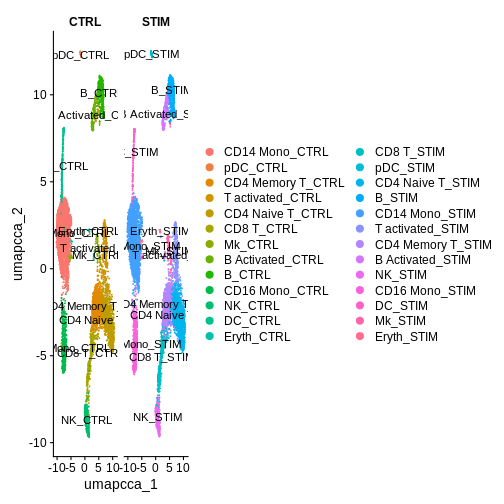
We’ll now leverage these new identities to compare DEGs between our treatment groups
R
treatment.response.CD16 <- FindMarkers(ifnb.filtered, ident.1 = 'CD16 Mono_STIM',
ident.2 = 'CD16 Mono_CTRL')
head(treatment.response.CD16) # These are the genes that are upregulated in the stimulated versus control group
OUTPUT
p_val avg_log2FC pct.1 pct.2 p_val_adj
IFIT1 1.379187e-176 5.834216 1.000 0.094 1.938172e-172
ISG15 6.273887e-166 5.333771 1.000 0.478 8.816694e-162
IFIT3 1.413978e-164 4.412990 0.992 0.314 1.987063e-160
ISG20 6.983755e-164 4.088510 1.000 0.448 9.814270e-160
IFITM3 1.056793e-161 3.191513 1.000 0.634 1.485111e-157
IFIT2 7.334976e-159 4.622453 0.974 0.162 1.030784e-154Step 4: Lets plot conserved features vs DEGs between conditions
R
FeaturePlot(ifnb.filtered, reduction = 'umap.cca',
features = c('VMO1', 'FCGR3A', 'IFIT1', 'ISG15'),
split.by = 'stim', min.cutoff = 'q10')
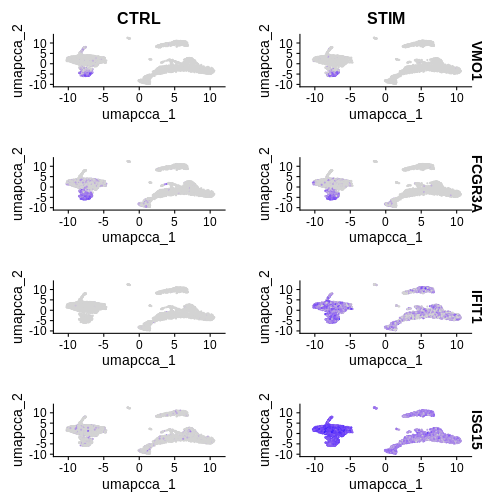
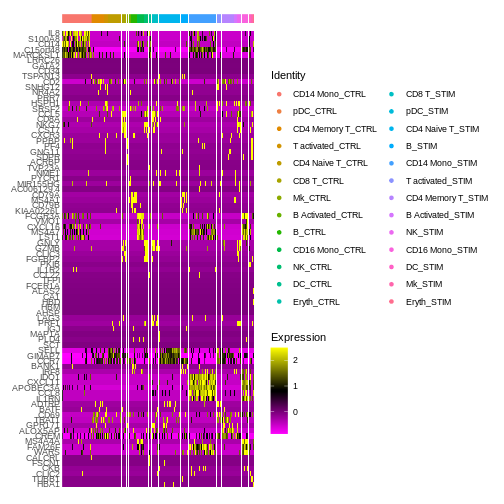
Step 5: Create a Heatmap to visualise DEGs between our two conditions + cell types
R
# Find upregulated genes in each group (cell type and condition)
ifnb.treatVsCtrl.markers <- FindAllMarkers(ifnb.filtered,
only.pos = TRUE)
R
saveRDS(ifnb.treatVsCtrl.markers, "ifnb_stimVsCtrl_markers.rds")
If the top code block takes too long to run - you can download the rds file of the output using the code below:
Seurat’s in-built heatmap function can be quite messy and hard to interpret sometimes (we’ll learn how to make better and clearer custom heatmaps using the pheatmap package from our Seurat expression data later on).
R
ifnb.treatVsCtrl.markers <- readRDS(url("https://github.com/manveerchauhan/Seurat_DE_Workshop/raw/refs/heads/main/ifnb_stimVsCtrl_markers.rds"))
top5 <- ifnb.treatVsCtrl.markers %>%
group_by(cluster) %>%
dplyr::filter(avg_log2FC > 1) %>%
slice_head(n = 5) %>%
ungroup()
DEG.heatmap <- DoHeatmap(ifnb.filtered, features = top5$gene,
label = FALSE)
DEG.heatmap
- QC filtering removes low-quality cells (e.g., low gene count or high mitochondrial %).
- Integration corrects sample-to-sample variation so cells group by biology, not by batch.
- Harmony and CCA both align shared cell states but use different mathematical strategies.
Content from Differential Expression using a pseudobulk approach and DESeq2
Last updated on 2025-12-02 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- Why aggregate to pseudobulk instead of testing each cell?
- How does donor act as the biological replicate in DESeq2?
- When do pseudobulk and single-cell DE agree or disagree, and why (e.g., zero inflation, composition, variance models)?
- What minimum sampling per group (cells per donor, donors per group) is sensible before aggregating?
Objectives
- Attach donor IDs to cells and create pseudobulk matrices with AggregateExpression().
- Run DESeq2 from Seurat via FindMarkers(test.use=“DESeq2”) on pseudobulk objects.
- Inspect and interpret key outputs (adjusted p-values, log2FC) and compare to single-cell DE.
- Visualize consensus/unique DEGs and make a publication-ready heatmap with pheatmap.
- Recognize pitfalls (uneven donor coverage, tiny groups, composition shifts) and report limitations.
OUTPUT
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 13548
Number of edges: 521570
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9002
Number of communities: 13
Elapsed time: 1 secondsStep 1: We need to import sample information for each cell from the original paper
Have a look at the ifnb.filtered seurat metadata, can you spot what we’ve done here?
R
# defining a function here to retrieve that information (code from https://satijalab.org/seurat/articles/de_vignette)
loadDonorMetadata <- function(seu.obj){
# load the inferred sample IDs of each cell
ctrl <- read.table(url("https://raw.githubusercontent.com/yelabucsf/demuxlet_paper_code/master/fig3/ye1.ctrl.8.10.sm.best"), head = T, stringsAsFactors = F)
stim <- read.table(url("https://raw.githubusercontent.com/yelabucsf/demuxlet_paper_code/master/fig3/ye2.stim.8.10.sm.best"), head = T, stringsAsFactors = F)
info <- rbind(ctrl, stim)
# rename the cell IDs by substituting the '-' into '.'
info$BARCODE <- gsub(pattern = "\\-", replacement = "\\.", info$BARCODE)
# only keep the cells with high-confidence sample ID
info <- info[grep(pattern = "SNG", x = info$BEST), ]
# remove cells with duplicated IDs in both ctrl and stim groups
info <- info[!duplicated(info$BARCODE) & !duplicated(info$BARCODE, fromLast = T), ]
# now add the sample IDs to ifnb
rownames(info) <- info$BARCODE
info <- info[, c("BEST"), drop = F]
names(info) <- c("donor_id")
seu.obj <- AddMetaData(seu.obj, metadata = info)
# remove cells without donor IDs
seu.obj$donor_id[is.na(seu.obj$donor_id)] <- "unknown"
seu.obj <- subset(seu.obj, subset = donor_id != "unknown")
return(seu.obj)
}
ifnb.filtered <- loadDonorMetadata(ifnb.filtered)
#ifnb.filtered@meta.data
Step 2: Aggregate our counts based on treatment group, cell-type, and donor id
Collapsing our single-cell matrix in this manner is referred to as creating a ‘pseudo-bulk’ count matrix.. We’re making a condensed count matrix that looks more like a bulk matrix so that we can use bulk differential expression algorithms like DESeq2. We can see this clearly when we have a look at the ifnb.pseudbulk.df we make in the following code block.
R
ifnb.pseudobulk <- AggregateExpression(ifnb.filtered, assays = "RNA",
group.by = c("stim", "donor_id", "seurat_annotations"),
return.seurat = TRUE)
OUTPUT
Centering and scaling data matrixR
## Centering and scaling data matrix
# If you want the pseudobulk matrix as a dataframe you can do this:
ifnb.pseudobulk.df <- AggregateExpression(ifnb.filtered, assays = "RNA",
group.by = c("stim", "donor_id", "seurat_annotations")) %>%
as.data.frame()
We can view the top rows here:
R
head(ifnb.pseudobulk.df)
Step 3: Perform Differential Expression using DESeq2
Just like before, lets make a new column containing the cell type and treatment group before DE with DESeq2. We do this so that we can leverage the Idents() function combined with the FindMarkers function.
To use DESeq2 in older versions of Seurat (prior to v5) we would have to perform a myriad of convoluted data wrangling steps to convert our Seurat pseudobulk matrix into a format compatible with DESeq2 (or whatever bulk DE package being used). Fortunately in Seurat v5, these different bulk DE algorithms/packages have been wrapped into the FindMarker() functions - simplifying pseudobulk DE approaches immensely.
It is worth taking a look at the Seurat DE vignette on your own to see the other pseudobulk DE methods you can use. Do keep in mind that to use some of the DE tests, you need to install that package and load it as a library separately to Seurat, as we’ve done here with DESeq2 at the start.
R
ifnb.pseudobulk$celltype.and.stim <- paste(ifnb.pseudobulk$seurat_annotations, ifnb.pseudobulk$stim, sep = "_")
Idents(ifnb.pseudobulk) <- "celltype.and.stim"
# Lets run a DEG test between treated and control CD 16 monocytes using the same FindMarkers function but with DESeq2
treatment.response.CD16.pseudo <- FindMarkers(object = ifnb.pseudobulk,
ident.1 = 'CD16 Mono_STIM',
ident.2 = 'CD16 Mono_CTRL',
test.use = "DESeq2")
OUTPUT
converting counts to integer modeOUTPUT
gene-wise dispersion estimatesOUTPUT
mean-dispersion relationshipOUTPUT
final dispersion estimatesR
head(treatment.response.CD16.pseudo)
OUTPUT
p_val avg_log2FC pct.1 pct.2 p_val_adj
IFIT3 1.564083e-134 4.601427 1 1 2.198006e-130
IFIT2 2.122691e-84 4.613021 1 1 2.983017e-80
ISG20 1.401656e-81 4.038272 1 1 1.969747e-77
DDX58 1.366535e-73 3.448721 1 1 1.920392e-69
NT5C3A 5.127048e-66 3.942571 1 1 7.205040e-62
OASL 1.186412e-63 4.025025 1 1 1.667265e-59R
# How are we able to use the same findmarkers function here?
head(Cells(ifnb.pseudobulk)) # our 'cells' are no longer barcodes, but have been renamed according to stim-donor-annotation when we aggregated our data earlier
OUTPUT
[1] "CTRL_SNG-101_CD14 Mono" "CTRL_SNG-101_CD4 Naive T"
[3] "CTRL_SNG-101_CD4 Memory T" "CTRL_SNG-101_CD16 Mono"
[5] "CTRL_SNG-101_B" "CTRL_SNG-101_CD8 T" Step 4: Assessing differences between our pseudbulk DEGs and single-cell DEGs
First lets take a look at the DEG dataframes we made for both.
Having a look at them, can you identify any differences? Can you think of any underlying reasons behind those differences?
Hint: Look at the p_val and p_val_adj columns.
R
head(treatment.response.CD16)
OUTPUT
p_val avg_log2FC pct.1 pct.2 p_val_adj
IFIT1 1.379187e-176 5.834216 1.000 0.094 1.938172e-172
ISG15 6.273887e-166 5.333771 1.000 0.478 8.816694e-162
IFIT3 1.413978e-164 4.412990 0.992 0.314 1.987063e-160
ISG20 6.983755e-164 4.088510 1.000 0.448 9.814270e-160
IFITM3 1.056793e-161 3.191513 1.000 0.634 1.485111e-157
IFIT2 7.334976e-159 4.622453 0.974 0.162 1.030784e-154R
head(treatment.response.CD16.pseudo)
OUTPUT
p_val avg_log2FC pct.1 pct.2 p_val_adj
IFIT3 1.564083e-134 4.601427 1 1 2.198006e-130
IFIT2 2.122691e-84 4.613021 1 1 2.983017e-80
ISG20 1.401656e-81 4.038272 1 1 1.969747e-77
DDX58 1.366535e-73 3.448721 1 1 1.920392e-69
NT5C3A 5.127048e-66 3.942571 1 1 7.205040e-62
OASL 1.186412e-63 4.025025 1 1 1.667265e-59Next let’s take a look at the degree of overlap between the actual DEGs in both approaches.
To help with this, I’m just going to define a couple helper functions below.
R
Merge_DEG_dataframes <- function(pseudobulk.de,
singlecell.de){
names(pseudobulk.de) <- paste0(names(pseudobulk.de), ".bulk")
pseudobulk.de$gene <- rownames(pseudobulk.de)
names(singlecell.de) <- paste0(names(singlecell.de), ".sc")
singlecell.de$gene <- rownames(singlecell.de)
merge_dat <- merge(singlecell.de, pseudobulk.de, by = "gene")
merge_dat <- merge_dat[order(merge_dat$p_val.bulk), ]
return(merge_dat)
}
Visualise_Overlapping_DEGs <- function(pseudobulk.de,
singlecell.de){
merge_dat <- Merge_DEG_dataframes(pseudobulk.de,
singlecell.de)
# Number of genes that are marginally significant in both; marginally significant only in bulk; and marginally significant only in single-cell
common <- merge_dat$gene[which(merge_dat$p_val_adj.bulk < 0.05 &
merge_dat$p_val_adj.sc < 0.05)]
only_sc <- merge_dat$gene[which(merge_dat$p_val_adj.bulk > 0.05 &
merge_dat$p_val_adj.sc < 0.05)]
only_pseudobulk <- merge_dat$gene[which(merge_dat$p_val_adj.bulk < 0.05 &
merge_dat$p_val_adj.sc > 0.05)]
# Create a dataframe to plot overlaps
overlap.info <- data.frame(
category = c("Common",
"Only in single-cell",
"Only in pseudobulk"),
count = c(length(common), length(only_sc), length(only_pseudobulk))
)
overlap.info$category <- factor(overlap.info$category,
levels = c("Common",
"Only in single-cell",
"Only in pseudobulk"))
# Create the bar plot
overlap.bar.plt <- ggplot(overlap.info, aes(x = category, y = count, fill = category)) +
geom_bar(stat = "identity") +
geom_text(aes(label = count), vjust = -0.5, size = 4) +
theme_minimal() +
labs(title = "Number of Overlapping and Unique DEGs from Single-Cell and Pseudobulk Tests",
x = "",
y = "Number of Genes") +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1))
return(overlap.bar.plt)
}
Let’s use the helper functions above to plot and view the overlap/agreement between our pseudobulk versus single-cell approaches
R
merged_deg_data <- Merge_DEG_dataframes(pseudobulk.de = treatment.response.CD16.pseudo,
singlecell.de = treatment.response.CD16)
merged_deg_data %>%
dplyr::select(gene,
p_val.sc, p_val.bulk,
p_val_adj.sc, p_val_adj.bulk) %>%
head(10)
OUTPUT
gene p_val.sc p_val.bulk p_val_adj.sc p_val_adj.bulk
2866 IFIT3 1.413978e-164 1.564083e-134 1.987063e-160 2.198006e-130
2865 IFIT2 7.334976e-159 2.122691e-84 1.030784e-154 2.983017e-80
2992 ISG20 6.983755e-164 1.401656e-81 9.814270e-160 1.969747e-77
1626 DDX58 2.340153e-109 1.366535e-73 3.288617e-105 1.920392e-69
4129 NT5C3A 5.806396e-117 5.127048e-66 8.159728e-113 7.205040e-62
4185 OASL 5.497910e-147 1.186412e-63 7.726213e-143 1.667265e-59
4544 PLSCR1 6.905174e-116 3.783863e-61 9.703841e-112 5.317463e-57
3859 MYL12A 2.476988e-83 7.623767e-61 3.480912e-79 1.071368e-56
2859 IFI35 4.701828e-99 2.527378e-58 6.607479e-95 3.551724e-54
2661 HERC5 1.578848e-92 1.829060e-56 2.218755e-88 2.570378e-52R
# How many DEGs overlap between our two methods? Is there anything in the merged_deg_data frame that stands out to you?
overlap.bar.plt <- Visualise_Overlapping_DEGs(pseudobulk.de = treatment.response.CD16.pseudo,
singlecell.de = treatment.response.CD16)
overlap.bar.plt
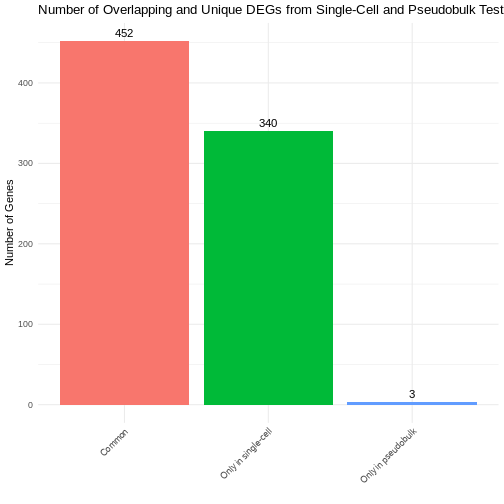
Can you explain why we’re seeing the discrepancies we see between the two methods here?
Step 5: Investigate the differences between pseudobulk DE and single-cell DE closer
Let’s create lists of genes in each of our categories first
R
common <- merged_deg_data$gene[which(merged_deg_data$p_val.bulk < 0.05 &
merged_deg_data$p_val.sc < 0.05)]
only_sc <- merged_deg_data$gene[which(merged_deg_data$p_val.bulk > 0.05 &
merged_deg_data$p_val.sc < 0.05)]
only_pseudobulk <- merged_deg_data$gene[which(merged_deg_data$p_val.bulk < 0.05 &
merged_deg_data$p_val.sc > 0.05)]
Now I want to look at the expression of genes that only appear in our sc deg test and not in our pseudobulk deg test I’ve picked two genes from the ‘only_sc’ variable we just defined
R
# create a new column to annotate sample-condition-celltype in the single-cell dataset
ifnb.filtered$donor_id.and.stim <- paste0(ifnb.filtered$stim, "-", ifnb.filtered$donor_id)
Idents(ifnb.filtered) <- "celltype.and.stim"
# Explore some genes that only appear in the sc deg test---
VlnPlot(ifnb.filtered, features = c("PABPC1", "SRGN"),
idents = c("CD16 Mono_CTRL", "CD16 Mono_STIM"),
group.by = "stim")
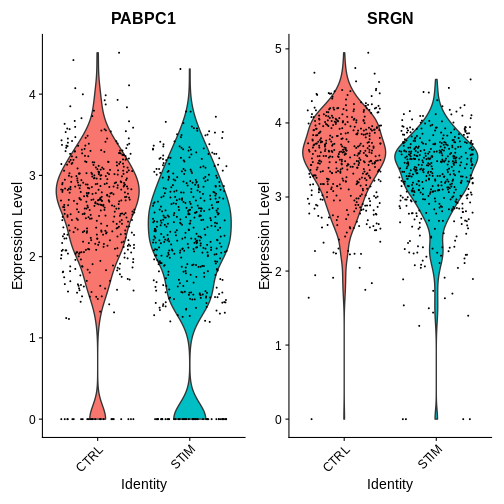
R
VlnPlot(ifnb.filtered, features = c("PABPC1", "SRGN"),
idents = c("CD16 Mono_CTRL", "CD16 Mono_STIM"),
group.by = "donor_id.and.stim", ncol = 1)
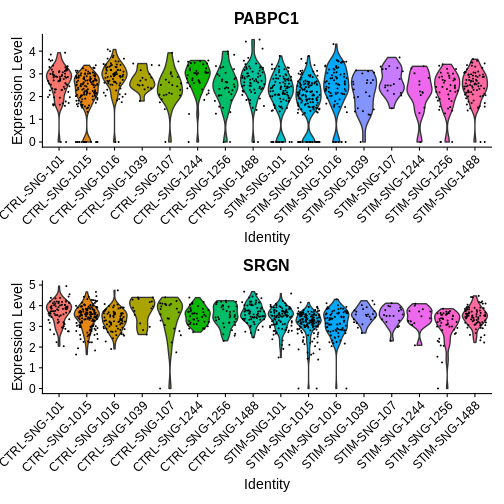
How would you interpret the plots above? What does this tell you about some of the pitfalls of single-cell DE approaches?
Now lets take a look at some genes that show agreement across both sc and pseudobulk deg tests
R
VlnPlot(ifnb.filtered, features = c("IFIT2", "PSMA4"),
idents = c("CD16 Mono_CTRL", "CD16 Mono_STIM"),
group.by = "stim")
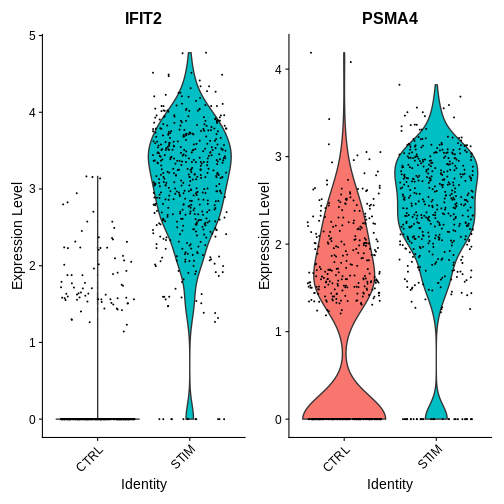
R
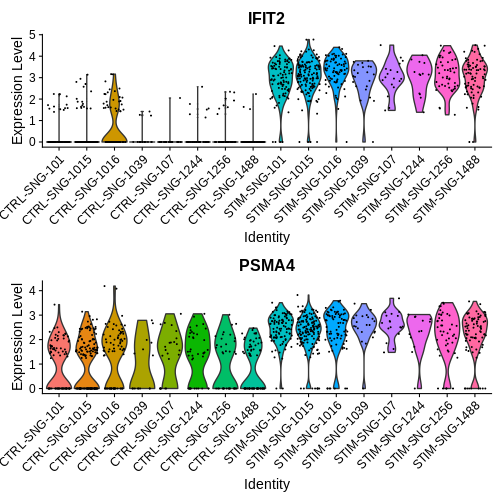
VlnPlot(ifnb.filtered, features = c("IFIT2", "PSMA4"),
idents = c("CD16 Mono_CTRL", "CD16 Mono_STIM"),
group.by = "donor_id.and.stim", ncol = 1)
Step 6: Creating our own custom visualisations for DEG analysis between cell-types in two different experimental groups
So far, we’ve been using functions wrapped within Seurat to plot and visualise our data. But we’re not limited to those functions. Let’s use the pheatmap (‘pretty heatmap’) package to visualise our DEGs with adjusted p values < 0.05.
First lets look at our significant DEGs as defined by our pseudobulk approach
R
CD16.sig.markers <- treatment.response.CD16.pseudo %>%
dplyr::filter(p_val_adj < 0.05) %>%
dplyr::mutate(gene = rownames(.))
This is how we can pull our average (scaled) pseudobulk expression values from our seurat obj:
R
ifnb.filtered$celltype.stim.donor_id <- paste0(ifnb.filtered$seurat_annotations, "-",
ifnb.filtered$stim, "-", ifnb.filtered$donor_id)
Idents(ifnb.filtered) <- "celltype.stim.donor_id"
all.sig.avg.Expression.mat <- AverageExpression(ifnb.filtered,
features = CD16.sig.markers$gene,
layer = 'scale.data')
OUTPUT
As of Seurat v5, we recommend using AggregateExpression to perform pseudo-bulk analysis.
This message is displayed once per session.R
## As of Seurat v5, we recommend using AggregateExpression to perform pseudo-bulk analysis.
## This message is displayed once per session.
# View(all.sig.avg.Expression.mat %>%
# as.data.frame())
Now lets make sure we’re only using data from the CD16 cell type
R
CD16.sig.avg.Expression.mat <- all.sig.avg.Expression.mat$RNA %>%
as.data.frame() %>%
dplyr::select(starts_with("CD16 Mono"))
# View(CD16.sig.avg.Expression.mat)
Let’s finally view our heatmap with averaged pseudobulk scaled expression values for our signficant DEGs
R
pheatmap::pheatmap(CD16.sig.avg.Expression.mat,
cluster_rows = TRUE,
show_rownames = FALSE,
border_color = NA,
fontsize = 10,
scale = "row",
fontsize_row = 10,
height = 20)
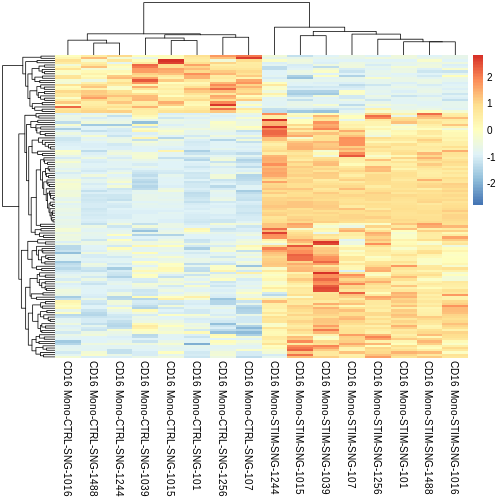
The cool thing about pheatmap is that we can customise our heatmap with added metadata
R
cluster_metadata <- data.frame(
row.names = colnames(CD16.sig.avg.Expression.mat)
) %>%
dplyr::mutate(
Cell_Type = "CD16 Mono",
Treatment_Group = ifelse(str_detect(row.names(.), "STIM|CTRL"),
str_extract(row.names(.), "STIM|CTRL")))
sig.DEG.heatmap <- pheatmap::pheatmap(CD16.sig.avg.Expression.mat,
cluster_rows = TRUE,
show_rownames = FALSE,
annotation = cluster_metadata[, c("Treatment_Group", "Cell_Type")],
border_color = NA,
fontsize = 10,
scale = "row",
fontsize_row = 10,
height = 20,
annotation_names_col = FALSE)
sig.DEG.heatmap
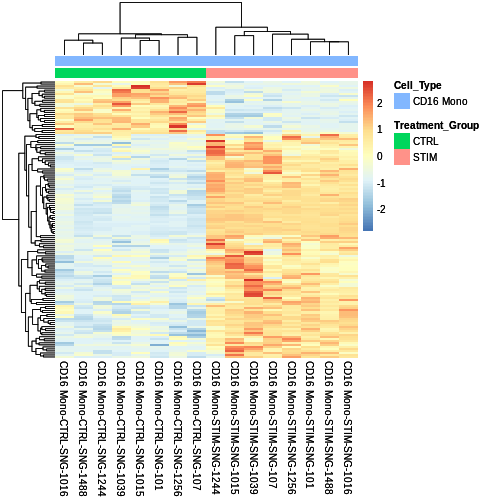
Lets save our heatmap using the grid library (very useful package!) Code from: https://stackoverflow.com/questions/43051525/how-to-draw-pheatmap-plot-to-screen-and-also-save-to-file
R
save_pheatmap_pdf <- function(x, filename, width=7, height=7) {
stopifnot(!missing(x))
stopifnot(!missing(filename))
pdf(filename, width=width, height=height)
grid::grid.newpage()
grid::grid.draw(x$gtable)
dev.off()
}
save_pheatmap_pdf(sig.DEG.heatmap, "sig_DEG_pseudo.pdf")
Challenge
Do the same thing with significant DEGs from the sc approach. Do you see any differences?
Run the same code as above but with the
treatment.response.CD16 variable instead of
treatment.response.CD16.pseudo variable.
R
CD16.sig.markers <- treatment.response.CD16 %>%
dplyr::filter(p_val_adj < 0.05) %>%
dplyr::mutate(gene = rownames(.))
ifnb.filtered$celltype.stim.donor_id <- paste0(ifnb.filtered$seurat_annotations, "-",
ifnb.filtered$stim, "-", ifnb.filtered$donor_id)
Idents(ifnb.filtered) <- "celltype.stim.donor_id"
all.sig.avg.Expression.mat <- AverageExpression(ifnb.filtered,
features = CD16.sig.markers$gene,
layer = 'scale.data')
## As of Seurat v5, we recommend using AggregateExpression to perform pseudo-bulk analysis.
## This message is displayed once per session.
# View(all.sig.avg.Expression.mat %>%
# as.data.frame())
CD16.sig.avg.Expression.mat <- all.sig.avg.Expression.mat$RNA %>%
as.data.frame() %>%
dplyr::select(starts_with("CD16 Mono"))
# View(CD16.sig.avg.Expression.mat)
pheatmap::pheatmap(CD16.sig.avg.Expression.mat,
cluster_rows = TRUE,
show_rownames = FALSE,
border_color = NA,
fontsize = 10,
scale = "row",
fontsize_row = 10,
height = 20)
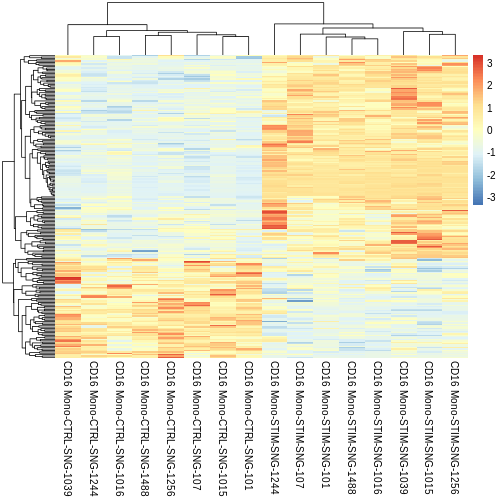
R
cluster_metadata <- data.frame(
row.names = colnames(CD16.sig.avg.Expression.mat)
) %>%
dplyr::mutate(
Cell_Type = "CD16 Mono",
Treatment_Group = ifelse(str_detect(row.names(.), "STIM|CTRL"),
str_extract(row.names(.), "STIM|CTRL")))
sig.DEG.heatmap <- pheatmap::pheatmap(CD16.sig.avg.Expression.mat,
cluster_rows = TRUE,
show_rownames = FALSE,
annotation = cluster_metadata[, c("Treatment_Group", "Cell_Type")],
border_color = NA,
fontsize = 10,
scale = "row",
fontsize_row = 10,
height = 20,
annotation_names_col = FALSE)
sig.DEG.heatmap
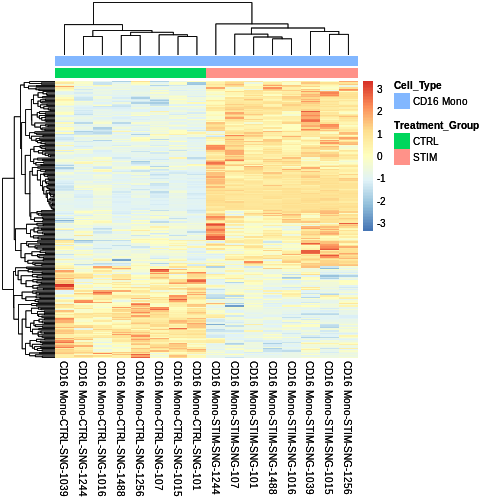
You have now completed the workshop!
Hopefully you’ve found this workshop useful and you’re now feeling more confident about using different integration and differential expression approaches in single-cell data analysis.
What kind of analyses do you think we can do next after obtaining a list of differentially expressed genes (DEGs) for each cell type and treatment groups?
- Collapse single-cell counts to pseudobulk per donor × condition × cell type.
- Compare single-cell DE vs pseudobulk DE.